FluidAudio: The SDK That Made Local Speech AI Practical
FluidAudio turned Parakeet from a research model into something any Swift developer can ship. Here's how it works, who built it, and why the SDK layer matters more than the model.
Everyone focuses on models. Whisper versus Parakeet. GPT versus Claude. Llama versus Gemma. The benchmarks, the parameter counts, the WER charts. But the thing that actually determines whether an AI model becomes useful on your device isn’t the model itself — it’s the software that sits between the model and the developer.
FluidAudio is that software for speech AI on Apple Silicon. And understanding what it does — and what it replaced — explains why local speech recognition went from a niche hobby to a production-ready capability in under a year.
The gap FluidAudio filled
By early 2025, NVIDIA’s Parakeet TDT was clearly the best open-source speech recognition model available. Smaller than Whisper (600 million parameters versus 1.5 billion), faster (non-autoregressive decoding), more accurate (under 3% word error rate on English). The benchmarks were decisive.
But running Parakeet on a Mac meant one of two options.
Option one: Python. Install NeMo, NVIDIA’s ML framework. Set up a Python environment. Download model weights. Write inference code. Manage the subprocess from your Swift app over JSON-RPC or some IPC mechanism. Handle crashes, restarts, serialization. Watch your GPU memory climb to 2 GB for a single model.
Option two: MLX. Use Apple’s machine learning framework through parakeet-mlx, a community port. Better than raw NeMo, but still Python. Still GPU memory. Still a subprocess. Still serialization overhead between your Swift app and a Python daemon.
Both options worked. Neither was something you’d want to ship to customers.
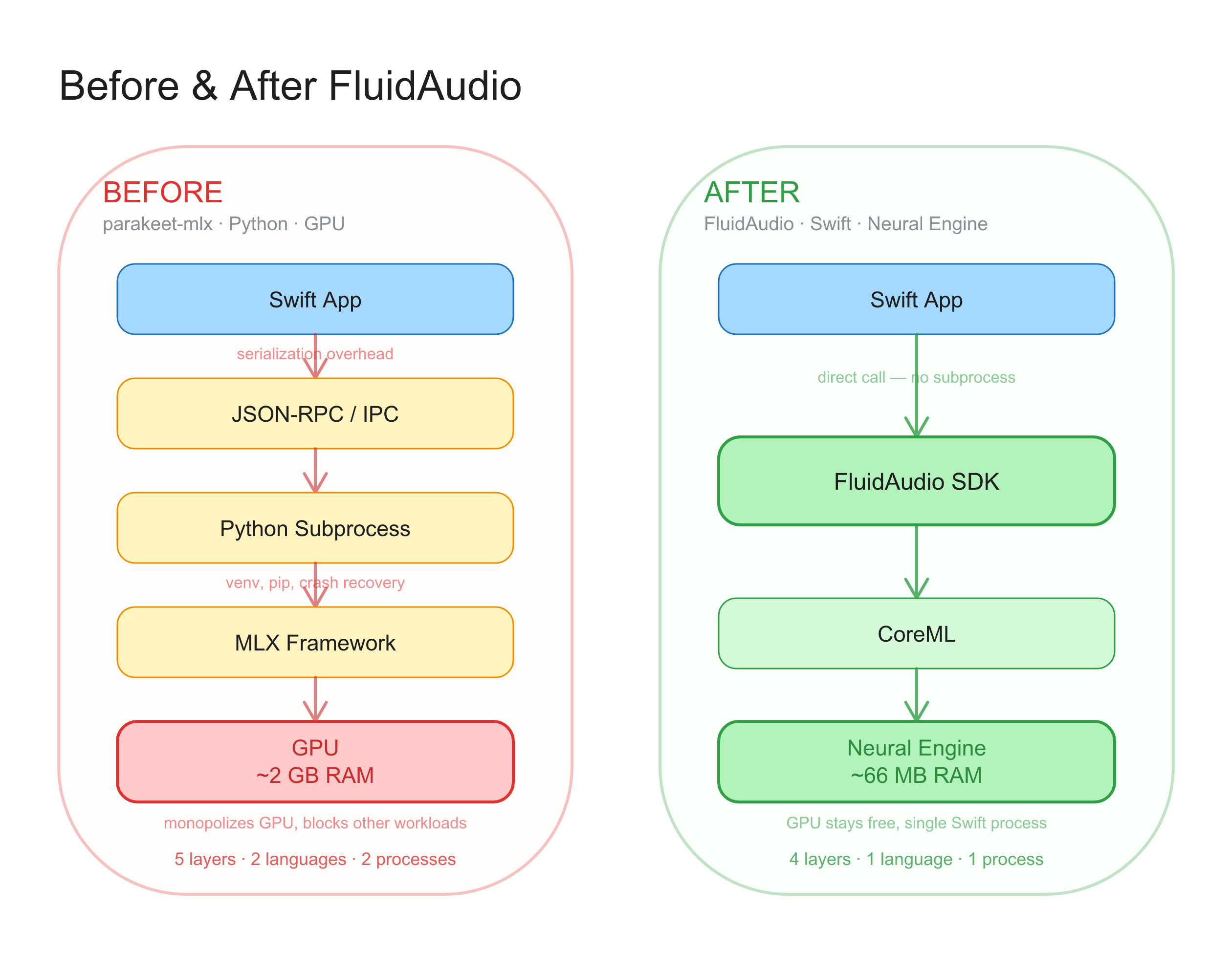
The problem wasn’t the model. The model was excellent. The problem was that no production-quality path existed between “NVIDIA publishes a research model” and “a Mac developer ships it in an app.” Converting a PyTorch model to CoreML, optimizing it for the Neural Engine, handling audio preprocessing, implementing the TDT decoder, managing model downloads — each step required specialized ML engineering knowledge that most app developers don’t have and shouldn’t need.
FluidAudio closed that gap entirely.
What FluidAudio actually is
FluidAudio is an open-source Swift SDK by Fluid Inference, a small applied AI research lab. Apache 2.0 license. The SDK handles everything between “I have audio” and “here’s the text”:
- Model download and caching from HuggingFace
- CoreML compilation for the Neural Engine
- Audio preprocessing (resampling to 16 kHz mono)
- Neural network inference on the ANE
- Token decoding with word-level timestamps and confidence scores
- Error recovery (corruption detection, automatic re-download)
From a developer’s perspective, it reduces speech recognition to three lines:
let models = try await AsrModels.downloadAndLoad(version: .v3)
let manager = AsrManager(config: .default)
try await manager.initialize(models: models)
let result = try await manager.transcribe(audioURL, source: .system)That’s it. No Python. No subprocess. No serialization. No GPU memory. The model runs on the Neural Engine, uses about 66 MB of working memory, and processes audio at 155-237x realtime depending on your chip.
The team
Fluid Inference was founded by Brandon Weng, who previously built Slipbox, a meeting notes app. The story is a familiar one in developer tools: he needed speech recognition for his own product, found the existing options inadequate, and ended up building the infrastructure layer instead.
The team brings experience from recommendation systems and content moderation platforms that served over a billion users. They describe their Mobius tool — an AI agent that automates CoreML model porting — as having “automated a CoreML port in ~12 hours versus 2 weeks, hit 0.99998 parity, and made it 3.5x faster.”
The project launched in June 2025. In nine months, it has shipped 37 releases, accumulated over 1,600 GitHub stars, and been adopted by 15+ production apps. The release cadence — roughly every one to two weeks — suggests active development backed by real user feedback.
How the internals work
FluidAudio’s architecture is worth understanding because it explains the performance numbers. The SDK partitions work across three compute domains — deliberately avoiding the GPU entirely.
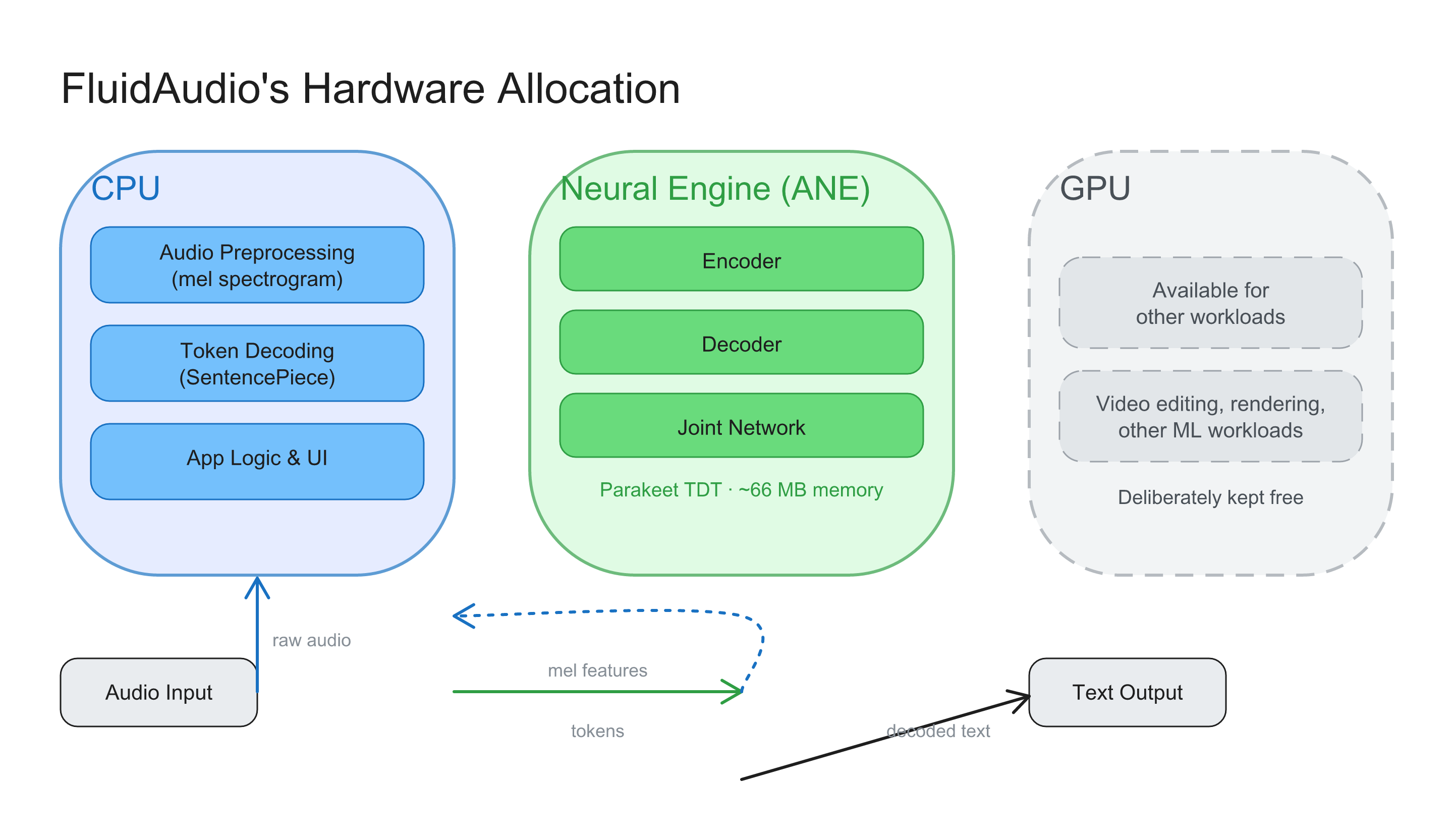
CPU: Audio preprocessing (mel spectrogram computation via Apple’s Accelerate framework) and token decoding (SentencePiece tokenization). These are sequential operations that the CPU handles efficiently.
Neural Engine: All neural network inference. The Parakeet TDT model consists of three neural networks — an encoder that processes audio features, a decoder that maintains language context, and a joint network that combines both to predict tokens and durations. All three run on the ANE.
GPU: Explicitly excluded. FluidAudio sets MLModelConfiguration.computeUnits = .cpuAndNeuralEngine, which prevents CoreML from falling back to the GPU. This is a deliberate architectural choice: the GPU stays free for rendering, video editing, or other workloads. On iOS, it has the additional benefit of avoiding background execution restrictions that Apple imposes on GPU compute.
The audio processing pipeline splits input into chunks of approximately 15 seconds with 2-second overlap. Each chunk processes independently — no context carryover between chunks — which enables parallel processing on hardware that supports it. The TDT decoder’s frame-skipping behavior means most of those 15-second chunks complete in well under 100 milliseconds on current hardware.
Memory optimization goes deep. FluidAudio uses float16 conversion with 64-byte alignment for Neural Engine memory access patterns, zero-copy feature providers that eliminate data copies between CPU and ANE, and Mach-level task APIs for memory monitoring. The result is the 66 MB working memory figure — roughly 30x less than GPU-based alternatives.
Beyond transcription
FluidAudio isn’t just an ASR SDK. The model catalog has expanded to cover most of the speech AI stack:
| Capability | Model | Performance |
|---|---|---|
| Batch transcription | Parakeet TDT v3 | 155-237x realtime, 2.5% WER |
| Streaming transcription | Parakeet EOU 120M | 4.87% WER at 320ms latency |
| Multilingual ASR | Qwen3-ASR 0.6B | 50+ languages, 1.2x realtime |
| Speaker diarization | Pyannote Community-1 | 122x realtime, 15% DER |
| Voice activity detection | Silero VAD | 1,230x realtime, 96% accuracy |
| Text-to-speech | Kokoro 82M | 23x realtime, 9 languages |
| Speaker embeddings | WeSpeaker | Speaker identification and verification |
Each model follows the same pattern: download, initialize, call. The SDK handles CoreML compilation, hardware routing, and memory management. Adding speaker diarization to an app that already uses FluidAudio for transcription is a few lines of code, not a second ML pipeline.
The Qwen3-ASR integration is particularly interesting. It’s a fundamentally different architecture from Parakeet — an encoder-decoder model, autoregressive like Whisper — which means it’s slower (1.2x realtime versus 155x+). But it covers languages Parakeet doesn’t: Mandarin, Japanese, Korean, Arabic, and dozens more. Having both models available through the same SDK API means a developer can route to Parakeet for European languages where it’s 100x faster, and fall back to Qwen3 for everything else. One SDK, two architectures, global coverage.
What the benchmarks show
An independent benchmark tested nine speech recognition implementations on the same hardware (M4 MacBook Pro) with the same audio:
| Implementation | Average time | Relative speed |
|---|---|---|
| FluidAudio (CoreML/ANE) | 0.19s | 1x (fastest) |
| Parakeet MLX (GPU) | 0.50s | 2.6x slower |
| MLX Whisper large-v3-turbo | 1.02s | 5.3x slower |
| whisper.cpp (q5_0) | 1.23s | 6.4x slower |
| WhisperKit | 2.22s | 11.5x slower |
| Whisper MPS | 5.37s | 28x slower |
Same model (Parakeet), different runtime: FluidAudio’s CoreML path is 2.6x faster than MLX. Different model (Parakeet vs. Whisper), same runtime approach (CoreML): FluidAudio is 11.5x faster than WhisperKit. The combination of a faster model architecture and a better-optimized runtime compounds.
The accuracy story is equally clear. Parakeet TDT v3 achieves 2.5% word error rate on LibriSpeech test-clean — competitive with or better than Whisper large-v3 — with 600 million parameters instead of 1.55 billion. And unlike Whisper, Parakeet doesn’t hallucinate. NVIDIA explicitly trained it on 36,000 hours of silence, noise, and non-speech audio paired with empty transcription targets. When there’s no speech, the model correctly produces no text.
Why the SDK layer matters
There’s a pattern in how technology becomes practical. A breakthrough model gets published. Researchers and hobbyists figure out how to run it. A few hackers build demos. Then someone builds the layer that makes it accessible to working developers, and adoption explodes.
Whisper had this arc: model release in 2022, whisper.cpp ports, then WhisperKit in early 2024 bringing CoreML and native Swift. Parakeet had it too: model release, parakeet-mlx port, then FluidAudio bringing CoreML and native Swift to the Neural Engine.
The SDK layer does work that’s invisible in a demo but essential in production. Audio format normalization — your app receives M4A but the model needs 16 kHz WAV. Model versioning — upgrading from v2 to v3 without breaking user data. Download resumption — a 6 GB model over flaky WiFi. Crash recovery — corrupted CoreML cache that needs to be detected and re-downloaded. Memory monitoring — making sure your app stays under system pressure limits on a base M1 with 8 GB of RAM.
None of this is glamorous. All of it is necessary. And the alternative — every app developer reimplementing model management, audio preprocessing, CoreML compilation, and Neural Engine optimization — is a waste of time that would produce worse results.
FluidAudio solved the speech AI infrastructure problem on Apple Silicon. The model was always good. The SDK made it usable.
The trajectory
Fluid Inference describes a three-phase vision: accessibility (smaller, task-specific models that outperform larger general ones), personalization (tools for building custom models without ML expertise), and ambient intelligence (models embedded in environments that evolve through learning).
The practical near-term roadmap is visible in recent releases. Inverse text normalization — converting “two hundred dollars” to “$200” — shipped in v0.12.2 with support for seven languages. Speaker pre-enrollment — recognizing known speakers by name — arrived in v0.12.3. Streaming diarization, voice cloning TTS, and grapheme-to-phoneme conversion are all in the SDK now.
The release cadence tells its own story. Thirty-seven releases in nine months. Real features, not point releases. Bug fixes that suggest production users hitting real edge cases. API additions that reflect developer requests. The kind of velocity that compounds.
For Mac developers building voice-powered applications, FluidAudio is the answer to a question that used to require months of ML engineering: how do I ship fast, accurate, private speech recognition to my users? Import the SDK. Initialize the model. Call transcribe. Everything else is handled.
MacParakeet uses FluidAudio to power both system-wide dictation and file transcription — Parakeet TDT running natively on the Neural Engine. Free and open-source.